Wednesday, November 12, 2014
SQL Server Job Run Time from SQL Agent
How to get run time for job total run time from history.
USE MSDB;
GO
select
j.name as 'JobName',
run_date,
run_time,
CONVERT(CHAR(8),DATEADD(second,run_time,0),108) AS Total_Run_Time,
h.message
From msdb.dbo.sysjobs j
INNER JOIN msdb.dbo.sysjobhistory h
ON j.job_id = h.job_id
where j.enabled = 1 --Only Enabled Jobs
and j.name = 'JOB_Name_Make_Change'
order by run_date desc
Tuesday, October 28, 2014
SQL Server Interview Questions
Note: I will be updating this post on a regular basis
1. I was wondering when inserting a record into this table, does it lock the whole table?
Ans: In SQL Server, by default, a table in not locked away when we are inserting data. If someone is accessing the same table, it will give them dirty-data read. However, coming back to original question, Not by default, but if you use the TABLOCK hint or if you're doing certain kinds of bulk load operations, then yes.
1. I was wondering when inserting a record into this table, does it lock the whole table?
Ans: In SQL Server, by default, a table in not locked away when we are inserting data. If someone is accessing the same table, it will give them dirty-data read. However, coming back to original question, Not by default, but if you use the TABLOCK hint or if you're doing certain kinds of bulk load operations, then yes.
Friday, October 24, 2014
sql if exists drop procedure
Many time, we when we are creating or alter an existing stored procedure, it is good practice to add this logic.
There are many way to this. Some of the method are described here.
IF EXISTS (SELECT * FROM sys.procedures WHERE object_id = OBJECT_ID(N'MyStandardStoredProcedureTemplate')
AND type in (N'P', N'PC'))
DROP PROCEDURE dbo.MyStandardStoredProcedureTemplate
Cost plan for this method is

There are many way to this. Some of the method are described here.
IF EXISTS (SELECT * FROM sys.procedures WHERE object_id = OBJECT_ID(N'MyStandardStoredProcedureTemplate')
AND type in (N'P', N'PC'))
DROP PROCEDURE dbo.MyStandardStoredProcedureTemplate
See the cost plan for this

Another way of doing this is
IF OBJECTPROPERTY(object_id('dbo.My ProcedureName'), N'IsProcedure') = 1
DROP PROCEDURE dbo.My ProcedureName
GO
Cost plan for this method is
The best practice is to create your stored procedure is to create your stored procedure and then use to alter to make changes as shown below.
USE Database_Name;
GO
SET ANSI_NULLS ON
GO
SET QUOTED_IDENTIFIER ON
GO
IF OBJECT_ID('dbo.MyStandardStoredProcedureTemplate') IS NULL -- Check if SP Exists
EXEC('CREATE PROCEDURE dbo.MyStandardStoredProcedureTemplate AS SET NOCOUNT ON;') -- Create dummy/empty SP to for Alter Statement
GO
ALTER PROCEDURE dbo.MyStandardStoredProcedureTemplate -- Alter the SP Always
AS
BEGIN
SET NOCOUNT ON;
SET XACT_ABORT ON;
---Declare All your variables Here's
DECLARE @Now datetime = getdate()
-- Error variables
, @ErrorProc varchar(128)
, @ErrorMessage varchar(1000)
, @ErrorLine int
, @ErrorSeverity int
, @ErrorState int
-- If you are creating a temp table, must add a script to drop before it go to create a table. See the example bellow
IF OBJECT_ID(N'tempdb..#MyTempTableForDataProcessing') IS NOT NULL
BEGIN
DROP TABLE #MyTempTableForDataProcessing
END
-- Now Create your temp table here.
Create Table #MyTempTableForDataProcessing
(ID int
, FirstName varchar(20)
, MiddleName varchar(10)
, LastName varchar(20)
)
-- If you are using a subquery in your select, you can populate it during intial stage to load data in buffer for faster select
--Uncomment below statement to your needs
--Insert Into #MyTempTableForDataProcessing
--Select ID,FirstName,MiddleName,LastName from Some_Parent_table
BEGIN TRY
-- Populated all your temp or your Select queries here in begin try section
BEGIN TRANSACTION
-- Do an actual data write on physical tables like delete, insert, update etcs.
Print 'Hello'
COMMIT Transaction
END TRY
BEGIN CATCH
IF (XACT_STATE()) <> 0
ROLLBACK TRANSACTION;
select
@ErrorProc = ERROR_PROCEDURE()
, @ErrorMessage = ERROR_MESSAGE()
, @ErrorLine = ERROR_LINE()
, @ErrorSeverity = ERROR_SEVERITY()
, @ErrorState = ERROR_STATE()
RAISERROR (
@ErrorMessage
, @ErrorSeverity
, @ErrorState
);
END CATCH
END
Thursday, September 25, 2014
SQL: How to Alter or Modify table in Production Environment
How to Alter or Modify table in Production Environment
Generally when we have to add a column, modify datatype or change column lenght,
we simply write Alter statement. This will work perfectly in any development environment as long as we as developer can revert back to starting point.
However in organization, DBA will ask you to check or if exist condition to any of your DDL scripts. So it's good practice to use
them even in Development environments. Being said that, let's look at how we can use these practice and make a habit of it.
Let's create a dummy table and we will walk through this.
CREATE TABLE dbo.Dummy_Table (
ID int
)
1. Adding a new column to an existing table.
Generally this is a statement which we are all familiar with:
Alter Table dbo.Dummy_Table Add FName Varchar(10)
The above statement will run any environment perfectly if this column does not exist in your table. However a good practice would be to
check if this column exist before we add a new column.
IF COL_LENGTH('dbo.Dummy_Table', 'FName') IS NULL
BEGIN
ALTER TABLE dbo.Dummy_Table ADD FName [varchar](10) NULL ;
END
Now if we re-run a simple statement
ALTER TABLE dbo.Dummy_Table ADD FName [varchar](10) NULL ;
Msg 2705, Level 16, State 4, Line 1
Column names in each table must be unique. Column name 'FName' in table 'dbo.Dummy_Table' is specified more than once.
it will throw an error because that column is already existing in given table.
But if we run this statement, if will be always executed without doing any change to actual table
IF COL_LENGTH('dbo.Dummy_Table', 'FName') IS NULL
BEGIN
ALTER TABLE dbo.Dummy_Table ADD FName [varchar](10) NULL ;
END
This way, we will be sure that
script won't fail in production environment and we don't make our DBA mad for giving them a script which can possibly fail.
2. Changing Column length of an existing column in a table
This is a general statement which we use to alter column length.
ALTER TABLE dbo.Dummy_Table ALTER COLUMN FName [varchar](15) NULL ;
Notice that in orginal table we have column length of 10 and now we are increasing to 15. We also know that column already exist in given table.
So we are checking to making sure that column length IS NOT NULL and if that statement is true we can change to any length we want.
IF COL_LENGTH('dbo.Dummy_Table', 'FName') IS NOT NULL
BEGIN
ALTER TABLE dbo.Dummy_Table ALTER COLUMN FName [varchar](15) NULL ;
END
Generally when we have to add a column, modify datatype or change column lenght,
we simply write Alter statement. This will work perfectly in any development environment as long as we as developer can revert back to starting point.
However in organization, DBA will ask you to check or if exist condition to any of your DDL scripts. So it's good practice to use
them even in Development environments. Being said that, let's look at how we can use these practice and make a habit of it.
Let's create a dummy table and we will walk through this.
CREATE TABLE dbo.Dummy_Table (
ID int
)
1. Adding a new column to an existing table.
Generally this is a statement which we are all familiar with:
Alter Table dbo.Dummy_Table Add FName Varchar(10)
The above statement will run any environment perfectly if this column does not exist in your table. However a good practice would be to
check if this column exist before we add a new column.
IF COL_LENGTH('dbo.Dummy_Table', 'FName') IS NULL
BEGIN
ALTER TABLE dbo.Dummy_Table ADD FName [varchar](10) NULL ;
END
Now if we re-run a simple statement
ALTER TABLE dbo.Dummy_Table ADD FName [varchar](10) NULL ;
Msg 2705, Level 16, State 4, Line 1
Column names in each table must be unique. Column name 'FName' in table 'dbo.Dummy_Table' is specified more than once.
it will throw an error because that column is already existing in given table.
But if we run this statement, if will be always executed without doing any change to actual table
IF COL_LENGTH('dbo.Dummy_Table', 'FName') IS NULL
BEGIN
ALTER TABLE dbo.Dummy_Table ADD FName [varchar](10) NULL ;
END
This way, we will be sure that
script won't fail in production environment and we don't make our DBA mad for giving them a script which can possibly fail.
2. Changing Column length of an existing column in a table
This is a general statement which we use to alter column length.
ALTER TABLE dbo.Dummy_Table ALTER COLUMN FName [varchar](15) NULL ;
Notice that in orginal table we have column length of 10 and now we are increasing to 15. We also know that column already exist in given table.
So we are checking to making sure that column length IS NOT NULL and if that statement is true we can change to any length we want.
IF COL_LENGTH('dbo.Dummy_Table', 'FName') IS NOT NULL
BEGIN
ALTER TABLE dbo.Dummy_Table ALTER COLUMN FName [varchar](15) NULL ;
END
Tuesday, August 5, 2014
RID Lookup in Sql Server
What is RID LOOKUP and how can we handle it.
A RID lookup is a lookup into a heap table ( A table without any clustered index. Even if we have a non-clustered index on heap table, it can act like a heap table). So in a RID lookup, a table is scanned using RowID (Row by Row that's why the name RID LOOKUP.
Generally Row ID is included in a non-clustered index in order to find the rest of a table's data in the heap table. Since a heap table is a table without a clustered index and rows are not sorted out in any order, it does a entire table scan.
To make sure that table does not do a RID LOOKUP, we can solve this issue by building a clustered index on a table.

A RID lookup is a lookup into a heap table ( A table without any clustered index. Even if we have a non-clustered index on heap table, it can act like a heap table). So in a RID lookup, a table is scanned using RowID (Row by Row that's why the name RID LOOKUP.
Generally Row ID is included in a non-clustered index in order to find the rest of a table's data in the heap table. Since a heap table is a table without a clustered index and rows are not sorted out in any order, it does a entire table scan.
To make sure that table does not do a RID LOOKUP, we can solve this issue by building a clustered index on a table.
Friday, August 1, 2014
How to convert date format from one varchar format to another varchar format??
Most of the time, when we design table, we store date in form of varchar format. Suppose we have a date of Birth column in varchar format "19890121" and for reporting purpose we have to take this column and format it in "01/21/1989" format.
If we try to use convert or cast function on a varchar date column and try to convert to another format, it won't work.
DECLARE @Date varchar(10) = '19890121'
Select convert(varchar(10), @Date, 101)
--> Result look like something this.
19890121
So how do we convert this Birthday column to our required format? For this we have to first convert varchar to date and then convert back to varchar in required format.
DECLARE @Date varchar(10) = '19890121'
Select convert(varchar(10), Cast(@Date as Date), 101)
--> Result
01/21/1989
Thursday, July 31, 2014
How to get list of all tables with Constraints in sql server
How to get list of all tables with Constraints in sql server?
There are different to get this information. Remember that all objects in a database is stored with an id in sys.objects table with its type.
If you do
Select * FROM sys.objects, you can see name, object_ID, principal_ID, schema_ID, parent_object_ID, type and type_desc with other information.
Type generally give you what kind of an object it is.
So this list will give you all the object type.
Select distinct type FROM sys.objects;

So to find all the table with Constraints, we can write simple SQL like this.
SELECT OBJECT_NAME(parent_object_id), type, type_desc FROM sys.objects WHERE type_desc LIKE '%cons%'
Another way to get same information is to use Table_Constraints. This table hold information about only those tables which has constraints.
SELECT *
FROM INFORMATION_SCHEMA.TABLE_CONSTRAINTS;
There are different to get this information. Remember that all objects in a database is stored with an id in sys.objects table with its type.
If you do
Select * FROM sys.objects, you can see name, object_ID, principal_ID, schema_ID, parent_object_ID, type and type_desc with other information.
Type generally give you what kind of an object it is.
So this list will give you all the object type.
Select distinct type FROM sys.objects;
So to find all the table with Constraints, we can write simple SQL like this.
SELECT OBJECT_NAME(parent_object_id), type, type_desc FROM sys.objects WHERE type_desc LIKE '%cons%'
Another way to get same information is to use Table_Constraints. This table hold information about only those tables which has constraints.
SELECT *
FROM INFORMATION_SCHEMA.TABLE_CONSTRAINTS;
Wednesday, July 23, 2014
Connecting from one server to another server using SQLCMD in Management Studio
In SQL Server Management Studio, most of the time, we have to change connection to different server to run same query to validate SQL Queries. To do so, we always use change connection feature by right clicking mouse and then changing to server where we want to run our queries.
There is another way to do so without going through all this using SQLCMD Command.
To do so add SQLCMD to your tool bar.
Then
Run this.
Select @@ServerName --> This give your current server Name
GO
:Connect ServerName --> This will change to your different serverName
Go
USE DatabaseName;
GO
Select GETUTCDATE()
Run your query here
That's it.
There is another way to do so without going through all this using SQLCMD Command.
To do so add SQLCMD to your tool bar.
Then
Run this.
Select @@ServerName --> This give your current server Name
GO
:Connect ServerName --> This will change to your different serverName
Go
USE DatabaseName;
GO
Select GETUTCDATE()
Run your query here
That's it.
Friday, May 30, 2014
Implementing SSIS Package Using File System.
Depending on how you or your organizations want to implement SSIS packagesduring Development, Test or Production environment, Let's see how we can do file system implementation. You can save your ssis package in either SQL Server Store or in a folder. I will be specially looking at File System implementation.
To do so, we will have to create following files first:
1. SSIS_Cmd.cmd
2. DB_cfg.dtsConfig
3. PackageName_ExeCfg.txt
So let's look at each of them:
SSIS_Cmd.cmd
This cmd file list where our sql server is installed, where our integration engine is running, our package directory, where we are saving our log file. Our database config, and how to handle error. You have to create just one file for a each server.
So let's look at the file itself:
++++++++++++++++++++++++++++++++++++++++++++++++++++++++++
set BIN=C:\Program Files (x86)\Microsoft SQL Server\100\DTS\Binn
set ROOTDIR=C:\SSIS
SetLocal EnableDelayedExpansion
set content=
for /F "delims=" %%i in (%1) do set %%i
set SSISPACKAGESDIR=%ROOTDIR%\%PACKAGEDIRNAME%\jobs\SSIS_Packages
set LOGDIR=%SSISPACKAGESDIR%\logs
"%BIN%\dtexec.exe" /FILE "%SSISPACKAGESDIR%\%SSISPACKAGE%" /CONFIGFILE "%SSISPACKAGESDIR%\%CONFIG_CUSTOM%" /CONFIGFILE "%ROOTDIR%\%CONFIG_DB%" /CHECKPOINTING OFF /REPORTING EWCDI 1>"%LOGDIR%\%LOGFILE%"
IF %errorlevel% NEQ 0 GOTO DTSRUN_ERR_EXIT
GOTO SUCCESS_EXIT
:DTSRUN_ERR_EXIT
echo.
echo ABENDED: ERROR running SSIS package
exit /B %errorlevel%
GOTO EXIT
:SUCCESS_EXIT
echo.
echo COMPLETED SUCCESSFULLY
GOTO EXIT
:EXIT
echo.
echo FINISHED: %date% %time%
echo on
EndLocal
+++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++
Next is DB_ConFig.cmd file
DB_cfg.dtsConfig
+++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++
<?xml version="1.0" encoding="utf-8"?>
<DTSConfiguration>
<DTSConfigurationHeading>
<DTSConfigurationFileInfo GeneratedBy="AMERICAS\straleyd" GeneratedFromPackageName="PackageName" GeneratedFromPackageID="{7DD1CDBA-6AD6-4D5D-84A0-4258BA92E894}" GeneratedDate="5/30/2014 10:01:10 AM" />
</DTSConfigurationHeading>
<Configuration ConfiguredType="Property" Path="\Package.Connections[Connection_Manager_Name].Properties[InitialCatalog]" ValueType="String">
<ConfiguredValue>DatabaseName</ConfiguredValue>
</Configuration>
<Configuration ConfiguredType="Property" Path="\Package.Connections[Connection_Manager_Name].Properties[Password]" ValueType="String">
<ConfiguredValue>Password!!!!!</ConfiguredValue>
</Configuration>
<Configuration ConfiguredType="Property" Path="\Package.Connections[Connection_Manager_Name].Properties[ServerName]" ValueType="String">
<ConfiguredValue>ServerName</ConfiguredValue>
</Configuration>
<Configuration ConfiguredType="Property" Path="\Package.Connections[Connection_Manager_Name].Properties[UserName]" ValueType="String">
<ConfiguredValue>USerLoginName!!!!</ConfiguredValue>
</Configuration>
</DTSConfiguration>
+++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++
PackageName_ExeCfg.txt
+++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++
SSISPACKAGE= SSIS_Package_Name.dtsx
PACKAGEDIRNAME=DevBox !!!!!!!!!!!Directory where you saving package file DevBox
CONFIG_CUSTOM=Config file of the package which you want to usecfg.dtsConfig
CONFIG_DB=DB_dev_Cfg.dtsConfig !!! DB Config file
LOGFILE=Name of Log File_log.txt
+++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++
To Implement.
Create all the necessary folders. For this I will take Development as folder Name
Inside Development Folder, I will create following folders:
archive -- if I have to archive any file from any of the package
inbound - folder to hold any files
Jobs- where I will save all my ssis package related files, and
outbound, if I have to write to any files.
Inside job folder, I will create two more folder
SSIS_EXEC and SSIS_Package
Inside SSIS_Package, I will save all the executable's related
For example say I create a dtsx file.
Example.dtsx - Package file
Example.dtsConfig --ConFig file
Example_Exe.txt - file with all the information.
Now go to sql server agent and create a job using Operating System (CMDEXEC) and List the path where you all the files are:
C:\SSIS\SSIS_Cmd.cmd C:\SSIS\Develpoment\jobs\ssis_packages\Example_ExeCfg.txt
and execute it.
To do so, we will have to create following files first:
1. SSIS_Cmd.cmd
2. DB_cfg.dtsConfig
3. PackageName_ExeCfg.txt
So let's look at each of them:
SSIS_Cmd.cmd
This cmd file list where our sql server is installed, where our integration engine is running, our package directory, where we are saving our log file. Our database config, and how to handle error. You have to create just one file for a each server.
So let's look at the file itself:
++++++++++++++++++++++++++++++++++++++++++++++++++++++++++
set BIN=C:\Program Files (x86)\Microsoft SQL Server\100\DTS\Binn
set ROOTDIR=C:\SSIS
SetLocal EnableDelayedExpansion
set content=
for /F "delims=" %%i in (%1) do set %%i
set SSISPACKAGESDIR=%ROOTDIR%\%PACKAGEDIRNAME%\jobs\SSIS_Packages
set LOGDIR=%SSISPACKAGESDIR%\logs
"%BIN%\dtexec.exe" /FILE "%SSISPACKAGESDIR%\%SSISPACKAGE%" /CONFIGFILE "%SSISPACKAGESDIR%\%CONFIG_CUSTOM%" /CONFIGFILE "%ROOTDIR%\%CONFIG_DB%" /CHECKPOINTING OFF /REPORTING EWCDI 1>"%LOGDIR%\%LOGFILE%"
IF %errorlevel% NEQ 0 GOTO DTSRUN_ERR_EXIT
GOTO SUCCESS_EXIT
:DTSRUN_ERR_EXIT
echo.
echo ABENDED: ERROR running SSIS package
exit /B %errorlevel%
GOTO EXIT
:SUCCESS_EXIT
echo.
echo COMPLETED SUCCESSFULLY
GOTO EXIT
:EXIT
echo.
echo FINISHED: %date% %time%
echo on
EndLocal
Next is DB_ConFig.cmd file
DB_cfg.dtsConfig
+++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++
<?xml version="1.0" encoding="utf-8"?>
<DTSConfiguration>
<DTSConfigurationHeading>
<DTSConfigurationFileInfo GeneratedBy="AMERICAS\straleyd" GeneratedFromPackageName="PackageName" GeneratedFromPackageID="{7DD1CDBA-6AD6-4D5D-84A0-4258BA92E894}" GeneratedDate="5/30/2014 10:01:10 AM" />
</DTSConfigurationHeading>
<Configuration ConfiguredType="Property" Path="\Package.Connections[Connection_Manager_Name].Properties[InitialCatalog]" ValueType="String">
<ConfiguredValue>DatabaseName</ConfiguredValue>
</Configuration>
<Configuration ConfiguredType="Property" Path="\Package.Connections[Connection_Manager_Name].Properties[Password]" ValueType="String">
<ConfiguredValue>Password!!!!!</ConfiguredValue>
</Configuration>
<Configuration ConfiguredType="Property" Path="\Package.Connections[Connection_Manager_Name].Properties[ServerName]" ValueType="String">
<ConfiguredValue>ServerName</ConfiguredValue>
</Configuration>
<Configuration ConfiguredType="Property" Path="\Package.Connections[Connection_Manager_Name].Properties[UserName]" ValueType="String">
<ConfiguredValue>USerLoginName!!!!</ConfiguredValue>
</Configuration>
</DTSConfiguration>
+++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++
PackageName_ExeCfg.txt
+++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++
SSISPACKAGE= SSIS_Package_Name.dtsx
PACKAGEDIRNAME=DevBox !!!!!!!!!!!Directory where you saving package file DevBox
CONFIG_CUSTOM=Config file of the package which you want to usecfg.dtsConfig
CONFIG_DB=DB_dev_Cfg.dtsConfig !!! DB Config file
LOGFILE=Name of Log File_log.txt
+++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++
To Implement.
Create all the necessary folders. For this I will take Development as folder Name
Inside Development Folder, I will create following folders:
archive -- if I have to archive any file from any of the package
inbound - folder to hold any files
Jobs- where I will save all my ssis package related files, and
outbound, if I have to write to any files.
Inside job folder, I will create two more folder
SSIS_EXEC and SSIS_Package
Inside SSIS_Package, I will save all the executable's related
For example say I create a dtsx file.
Example.dtsx - Package file
Example.dtsConfig --ConFig file
Example_Exe.txt - file with all the information.
Now go to sql server agent and create a job using Operating System (CMDEXEC) and List the path where you all the files are:
C:\SSIS\SSIS_Cmd.cmd C:\SSIS\Develpoment\jobs\ssis_packages\Example_ExeCfg.txt
and execute it.
Thursday, May 8, 2014
Sql Server: Stored Procedure to backup databases
Sql Server: Stored Procedure to backup databases
Here's an example of Stored Procedure which uses cursor to backup all your databases.
Go to Master database
USE MASTER
GO;
And then create this stored Procedure. Change your path to where you want to do the backup.
-- SP using cursor to back up database
Create Procedure sp_databases_backup
As
BEGIN
set nocount on
set xact_abort on
Declare @name varchar(128) --database name
Declare @path varchar(256) --Path to backup database file
Declare @filename varchar(128) -- name of database backup file
Declare @fileDate varchar(20) --Date when the database was backup
SET @path = 'C:\backup\'
SET @fileDate = convert(varchar(20), getdate(),112)
DECLARE db_cursor CURSOR FOR
Select name from dbo.sysdatabases
Where name NOT IN ('master', 'model', 'msdb', 'tempdb')
OPEN db_cursor
FETCH NEXT from db_cursor INTO @name
WHILE @@Fetch_status = 0
BEGIN
SET @filename = @path+@name+'_'+@fileDate+'.Bak'
BACKUP DATABASE @name TO DISK =@filename
FETCH NEXT FROM db_cursor INTO @name
END
CLOSE db_cursor
Deallocate db_cursor
END
Here's an example of Stored Procedure which uses cursor to backup all your databases.
Go to Master database
USE MASTER
GO;
And then create this stored Procedure. Change your path to where you want to do the backup.
-- SP using cursor to back up database
Create Procedure sp_databases_backup
As
BEGIN
set nocount on
set xact_abort on
Declare @name varchar(128) --database name
Declare @path varchar(256) --Path to backup database file
Declare @filename varchar(128) -- name of database backup file
Declare @fileDate varchar(20) --Date when the database was backup
SET @path = 'C:\backup\'
SET @fileDate = convert(varchar(20), getdate(),112)
DECLARE db_cursor CURSOR FOR
Select name from dbo.sysdatabases
Where name NOT IN ('master', 'model', 'msdb', 'tempdb')
OPEN db_cursor
FETCH NEXT from db_cursor INTO @name
WHILE @@Fetch_status = 0
BEGIN
SET @filename = @path+@name+'_'+@fileDate+'.Bak'
BACKUP DATABASE @name TO DISK =@filename
FETCH NEXT FROM db_cursor INTO @name
END
CLOSE db_cursor
Deallocate db_cursor
END
Thursday, May 1, 2014
SQL Server: Keeping track of changing data in a table
Sometime we are asked to keep a track of how data are changing over time in a table. This is critical in DW world. If they have (most of the time, they have Enterprise Edition so they can implement CDC method).
However there are some simple method we can use to keep track of data change for Insert/Update/Deleted.
Let's see how we can do this.
Steps 1. Let's create a table where we want to keep track of data change.
SET ANSI_NULLS ON
GO
SET QUOTED_IDENTIFIER ON
GO
CREATE TABLE [UserTable](
ID [int] IDENTITY(1,1) NOT NULL,
FName varchar(20) NOT NULL,
LName varchar(20) NOT NULL,
Address1 varchar(40),
Address2 varchar(40),
City varchar(20) NOT NULL,
ZipCode varchar(10),
[StateCode] varchar(2) NOT NULL,
CreatedDate Datetime NOT NULL,
CreateBy int,
UpdatedDate Datetime NOT NULL,
UpdatedBy int
CONSTRAINT [PK_UserTable] PRIMARY KEY CLUSTERED
(
[ID] ASC
)WITH (PAD_INDEX = OFF, STATISTICS_NORECOMPUTE = OFF, IGNORE_DUP_KEY = OFF, ALLOW_ROW_LOCKS = ON, ALLOW_PAGE_LOCKS = ON, FILLFACTOR = 80) ON [PRIMARY]
) ON [PRIMARY]
GO
Step 2.Let's create a archive table where we will keep track of all the data that is changing in above table.
SET ANSI_NULLS ON
GO
SET QUOTED_IDENTIFIER ON
GO
SET ANSI_PADDING ON
GO
CREATE TABLE [UserTable_Archive](
[ArchiveID] [bigint] IDENTITY(1,1) NOT NULL,
[ArchiveDate] [datetime] NOT NULL,
[ArchiveAction] [varchar](3) NOT NULL,
ID [int] NOT NULL,
FName varchar(20) NOT NULL,
LName varchar(20) NOT NULL,
Address1 varchar(40),
Address2 varchar(40),
City varchar(20) NOT NULL,
ZipCode varchar(10),
[StateCode] varchar(2) NOT NULL,
CreatedDate Datetime NOT NULL,
CreateBy int,
UpdatedDate Datetime NOT NULL,
UpdatedBy int
CONSTRAINT [PK_ArchiveID_Archive] PRIMARY KEY CLUSTERED
(
[ArchiveID] ASC
)WITH (PAD_INDEX = OFF, STATISTICS_NORECOMPUTE = OFF, IGNORE_DUP_KEY = OFF, ALLOW_ROW_LOCKS = ON, ALLOW_PAGE_LOCKS = ON, FILLFACTOR = 80) ON [PRIMARY]
) ON [PRIMARY]
GO
SET ANSI_PADDING OFF
GO
ALTER TABLE [UserTable_Archive] ADD CONSTRAINT [DF_UserTable_ArchiveDate] DEFAULT (getdate()) FOR [ArchiveDate]
GO
--Step 3. Let's write trigger for Update/Delete/Insert
SET ANSI_NULLS ON
GO
SET QUOTED_IDENTIFIER ON
GO
create trigger UserTable_Archive_Delete
on UserTable for delete
as
insert UserTable_Archive (
[ArchiveDate]
, [ArchiveAction]
, ID
, FName
, LName
, Address1
, Address2
, City
, ZipCode
, [StateCode]
, CreatedDate
, CreateBy
, UpdatedDate
, UpdatedBy
)
select
getdate()
, 'DLT'
, ID
, FName
, LName
, Address1
, Address2
, City
, ZipCode
, [StateCode]
, CreatedDate
, CreateBy
, UpdatedDate
, UpdatedBy
from deleted
GO
create trigger UserTable_Archive_Insert
on UserTable for Insert
as
insert UserTable_Archive (
[ArchiveDate]
, [ArchiveAction]
, ID
, FName
, LName
, Address1
, Address2
, City
, ZipCode
, [StateCode]
, CreatedDate
, CreateBy
, UpdatedDate
, UpdatedBy
)
select
getdate()
, 'INSERT'
, ID
, FName
, LName
, Address1
, Address2
, City
, ZipCode
, [StateCode]
, CreatedDate
, CreateBy
, UpdatedDate
, UpdatedBy
from INSERTED
GO
create trigger UserTable_Archive_Update
on UserTable for Update
as
insert UserTable_Archive (
[ArchiveDate]
, [ArchiveAction]
, ID
, FName
, LName
, Address1
, Address2
, City
, ZipCode
, [StateCode]
, CreatedDate
, CreateBy
, UpdatedDate
, UpdatedBy
)
select
getdate()
, 'UPD'
, ID
, FName
, LName
, Address1
, Address2
, City
, ZipCode
, [StateCode]
, CreatedDate
, CreateBy
, UpdatedDate
, UpdatedBy
from Inserted
GO
Step 4: Let's insert some data and see how it is implemented.
Insert into UserTable (FName ,LName,Address1 , Address2 , City , ZipCode , [StateCode], CreatedDate , CreateBy, UpdatedDate , UpdatedBy ) Values ('Mary','Stephon', '2250 Rock Road', '231', 'Dallas', '123456', 'TX', getdate() , 0, getdate(), 0)
Insert into UserTable (FName ,LName,Address1 , Address2 , City , ZipCode , [StateCode], CreatedDate , CreateBy, UpdatedDate , UpdatedBy ) Values ('Mary','Jane', '2251 Rock Road', '231', 'Dallas', '123456', 'TX', getdate() , 0, getdate(), 0)
Insert into UserTable (FName ,LName,Address1 , Address2 , City , ZipCode , [StateCode], CreatedDate , CreateBy, UpdatedDate , UpdatedBy ) Values ('Mary','Simon', '2252 Rock Road', '231', 'Dallas', '123456', 'TX', getdate() , 0, getdate(), 0)
Insert into UserTable (FName ,LName,Address1 , Address2 , City , ZipCode , [StateCode], CreatedDate , CreateBy, UpdatedDate , UpdatedBy )Values ('Mary','Colbert', '2253 Rock Road', '231', 'Dallas', '123456', 'TX', getdate() , 0, getdate(), 0)
Select * FROM UserTable;
Select * from UserTable_Archive;

Similary Let's do some update/Delete to existing data
Update UserTable
Set FName = 'Lisa'
Where LName = 'Jane'
Delete UserTable
where LName = 'Colbert'

There you go. However there is some cost associated with this method.
However there are some simple method we can use to keep track of data change for Insert/Update/Deleted.
Let's see how we can do this.
Steps 1. Let's create a table where we want to keep track of data change.
SET ANSI_NULLS ON
GO
SET QUOTED_IDENTIFIER ON
GO
CREATE TABLE [UserTable](
ID [int] IDENTITY(1,1) NOT NULL,
FName varchar(20) NOT NULL,
LName varchar(20) NOT NULL,
Address1 varchar(40),
Address2 varchar(40),
City varchar(20) NOT NULL,
ZipCode varchar(10),
[StateCode] varchar(2) NOT NULL,
CreatedDate Datetime NOT NULL,
CreateBy int,
UpdatedDate Datetime NOT NULL,
UpdatedBy int
CONSTRAINT [PK_UserTable] PRIMARY KEY CLUSTERED
(
[ID] ASC
)WITH (PAD_INDEX = OFF, STATISTICS_NORECOMPUTE = OFF, IGNORE_DUP_KEY = OFF, ALLOW_ROW_LOCKS = ON, ALLOW_PAGE_LOCKS = ON, FILLFACTOR = 80) ON [PRIMARY]
) ON [PRIMARY]
GO
Step 2.Let's create a archive table where we will keep track of all the data that is changing in above table.
SET ANSI_NULLS ON
GO
SET QUOTED_IDENTIFIER ON
GO
SET ANSI_PADDING ON
GO
CREATE TABLE [UserTable_Archive](
[ArchiveID] [bigint] IDENTITY(1,1) NOT NULL,
[ArchiveDate] [datetime] NOT NULL,
[ArchiveAction] [varchar](3) NOT NULL,
ID [int] NOT NULL,
FName varchar(20) NOT NULL,
LName varchar(20) NOT NULL,
Address1 varchar(40),
Address2 varchar(40),
City varchar(20) NOT NULL,
ZipCode varchar(10),
[StateCode] varchar(2) NOT NULL,
CreatedDate Datetime NOT NULL,
CreateBy int,
UpdatedDate Datetime NOT NULL,
UpdatedBy int
CONSTRAINT [PK_ArchiveID_Archive] PRIMARY KEY CLUSTERED
(
[ArchiveID] ASC
)WITH (PAD_INDEX = OFF, STATISTICS_NORECOMPUTE = OFF, IGNORE_DUP_KEY = OFF, ALLOW_ROW_LOCKS = ON, ALLOW_PAGE_LOCKS = ON, FILLFACTOR = 80) ON [PRIMARY]
) ON [PRIMARY]
GO
SET ANSI_PADDING OFF
GO
ALTER TABLE [UserTable_Archive] ADD CONSTRAINT [DF_UserTable_ArchiveDate] DEFAULT (getdate()) FOR [ArchiveDate]
GO
--Step 3. Let's write trigger for Update/Delete/Insert
SET ANSI_NULLS ON
GO
SET QUOTED_IDENTIFIER ON
GO
create trigger UserTable_Archive_Delete
on UserTable for delete
as
insert UserTable_Archive (
[ArchiveDate]
, [ArchiveAction]
, ID
, FName
, LName
, Address1
, Address2
, City
, ZipCode
, [StateCode]
, CreatedDate
, CreateBy
, UpdatedDate
, UpdatedBy
)
select
getdate()
, 'DLT'
, ID
, FName
, LName
, Address1
, Address2
, City
, ZipCode
, [StateCode]
, CreatedDate
, CreateBy
, UpdatedDate
, UpdatedBy
from deleted
GO
create trigger UserTable_Archive_Insert
on UserTable for Insert
as
insert UserTable_Archive (
[ArchiveDate]
, [ArchiveAction]
, ID
, FName
, LName
, Address1
, Address2
, City
, ZipCode
, [StateCode]
, CreatedDate
, CreateBy
, UpdatedDate
, UpdatedBy
)
select
getdate()
, 'INSERT'
, ID
, FName
, LName
, Address1
, Address2
, City
, ZipCode
, [StateCode]
, CreatedDate
, CreateBy
, UpdatedDate
, UpdatedBy
from INSERTED
GO
create trigger UserTable_Archive_Update
on UserTable for Update
as
insert UserTable_Archive (
[ArchiveDate]
, [ArchiveAction]
, ID
, FName
, LName
, Address1
, Address2
, City
, ZipCode
, [StateCode]
, CreatedDate
, CreateBy
, UpdatedDate
, UpdatedBy
)
select
getdate()
, 'UPD'
, ID
, FName
, LName
, Address1
, Address2
, City
, ZipCode
, [StateCode]
, CreatedDate
, CreateBy
, UpdatedDate
, UpdatedBy
from Inserted
GO
Step 4: Let's insert some data and see how it is implemented.
Insert into UserTable (FName ,LName,Address1 , Address2 , City , ZipCode , [StateCode], CreatedDate , CreateBy, UpdatedDate , UpdatedBy ) Values ('Mary','Stephon', '2250 Rock Road', '231', 'Dallas', '123456', 'TX', getdate() , 0, getdate(), 0)
Insert into UserTable (FName ,LName,Address1 , Address2 , City , ZipCode , [StateCode], CreatedDate , CreateBy, UpdatedDate , UpdatedBy ) Values ('Mary','Jane', '2251 Rock Road', '231', 'Dallas', '123456', 'TX', getdate() , 0, getdate(), 0)
Insert into UserTable (FName ,LName,Address1 , Address2 , City , ZipCode , [StateCode], CreatedDate , CreateBy, UpdatedDate , UpdatedBy ) Values ('Mary','Simon', '2252 Rock Road', '231', 'Dallas', '123456', 'TX', getdate() , 0, getdate(), 0)
Insert into UserTable (FName ,LName,Address1 , Address2 , City , ZipCode , [StateCode], CreatedDate , CreateBy, UpdatedDate , UpdatedBy )Values ('Mary','Colbert', '2253 Rock Road', '231', 'Dallas', '123456', 'TX', getdate() , 0, getdate(), 0)
Select * FROM UserTable;
Select * from UserTable_Archive;
Similary Let's do some update/Delete to existing data
Update UserTable
Set FName = 'Lisa'
Where LName = 'Jane'
Delete UserTable
where LName = 'Colbert'
And then let's see how data looks
Select * FROM UserTable;
Select * from UserTable_Archive;
There you go. However there is some cost associated with this method.
Thursday, March 27, 2014
SQL To check for a day of a month
Suppose, You are asked to design a SSIS package which should run on every 'Friday' of the week except for Friday which falls on 1st day of the month. For example November 1, 2013. This day is Friday and first day of the month. So in our case this package should not run.
Assumption: You have a table called Calendartable with calendarDate, calendarYearMonth column
Sample data should look like
20140101, 201401
20140102, 201401
Let's first write T-SQL code to find out if it Friday and FirstDay of the month.
declare
@RunDate date
, @RunDate_YearMonth varchar(6)
, @ProcessingDateForThisMonth date
, @ProcessPackage int = 0
set @RunDate = '11/01/2013'
select @RunDate_YearMonth = CalendarDate from Calendartable where CalendarDate = @RunDate
Print @RunDate_YearMonth;
select @ProcessingDateForThisMonth = min(CalendarDate) from Calendartable
where CalendarYearMonthCode = @RunDate_YearMonth --same month as run date
and datename(dw, CalendarDate) = 'Friday' --day is a Friday
and day(CalendarDate) > 1 --not the 1st day of the month
Print @ProcessingDateForThisMonth
if @RunDate = @ProcessingDateForThisMonth
begin
set @ProcessPackage = 1
end
else
begin
set @ProcessPackage = 0
end
print @ProcessPackage
This sql set the value of ProcessPackage to 0 or 1 depending upon the date and datename. It will set to value of 0 only when the day happen to be firstday of the month and its friday otherwise it will be always 0.
Put Execute SQL Task in your package and take the value as your output value.
Declare @Now Date, @dayofmonth int=0, @ProcessPackage int = 0
Set @Now = getdate()
Set @dayofmonth = day(@now)
IF (@dayofmonth = 1 and datename(dw,@now) = 'Friday')
Set @ProcessPackage = 0
ELSE
SET @ProcessPackage = 1
Select @ProcessPackage



At this point, you should be ready to execute rest of your package based on this value
Assumption: You have a table called Calendartable with calendarDate, calendarYearMonth column
Sample data should look like
20140101, 201401
20140102, 201401
Let's first write T-SQL code to find out if it Friday and FirstDay of the month.
declare
@RunDate date
, @RunDate_YearMonth varchar(6)
, @ProcessingDateForThisMonth date
, @ProcessPackage int = 0
set @RunDate = '11/01/2013'
select @RunDate_YearMonth = CalendarDate from Calendartable where CalendarDate = @RunDate
Print @RunDate_YearMonth;
select @ProcessingDateForThisMonth = min(CalendarDate) from Calendartable
where CalendarYearMonthCode = @RunDate_YearMonth --same month as run date
and datename(dw, CalendarDate) = 'Friday' --day is a Friday
and day(CalendarDate) > 1 --not the 1st day of the month
Print @ProcessingDateForThisMonth
if @RunDate = @ProcessingDateForThisMonth
begin
set @ProcessPackage = 1
end
else
begin
set @ProcessPackage = 0
end
print @ProcessPackage
This sql set the value of ProcessPackage to 0 or 1 depending upon the date and datename. It will set to value of 0 only when the day happen to be firstday of the month and its friday otherwise it will be always 0.
Put Execute SQL Task in your package and take the value as your output value.
Declare @Now Date, @dayofmonth int=0, @ProcessPackage int = 0
Set @Now = getdate()
Set @dayofmonth = day(@now)
IF (@dayofmonth = 1 and datename(dw,@now) = 'Friday')
Set @ProcessPackage = 0
ELSE
SET @ProcessPackage = 1
Select @ProcessPackage
At this point, you should be ready to execute rest of your package based on this value
Monday, March 3, 2014
SQL Server: Converting Integer to Binary data
Let's first a create table which will be use to demonstrate conversion of integer to binary values. To keep this thing simple, let's keep our table as small as possible.
Create table NumberTable
(NumberID int IDENTITY Primary Key NOT NULL
,Number int
,Number_Name varchar(100)
)
--Let's insert some data in this table
Insert into NumberTable
VALUES (1, 'One'), (2, 'Two'), (3, 'Three'), (4, 'Four'), (5, 'Five')
-- Let's see what we have in this table.
Select * from Number;
--Let's convert this number to binary value. To do so, we will use Common Table Expression
With BinaryConversation AS
(Select Number, Number as WorkingNumber, cast('' as varchar(max)) as binary_values from NumberTable
-- Now we will do Union ALL with converted values from Common table Expression
UNION ALL
Select B.Number, B.WorkingNumber/2, cast(B.WorkingNumber%2 as varchar(max))+B.binary_values
FROM BinaryConversation B
Where WorkingNumber > 0) --This condition keep our results set to only converted values)
Select Number, binary_values from BinaryConversation Where WorkingNumber = 0
Order BY Number
;

Create table NumberTable
(NumberID int IDENTITY Primary Key NOT NULL
,Number int
,Number_Name varchar(100)
)
--Let's insert some data in this table
Insert into NumberTable
VALUES (1, 'One'), (2, 'Two'), (3, 'Three'), (4, 'Four'), (5, 'Five')
-- Let's see what we have in this table.
Select * from Number;
--Let's convert this number to binary value. To do so, we will use Common Table Expression
With BinaryConversation AS
(Select Number, Number as WorkingNumber, cast('' as varchar(max)) as binary_values from NumberTable
-- Now we will do Union ALL with converted values from Common table Expression
UNION ALL
Select B.Number, B.WorkingNumber/2, cast(B.WorkingNumber%2 as varchar(max))+B.binary_values
FROM BinaryConversation B
Where WorkingNumber > 0) --This condition keep our results set to only converted values)
Select Number, binary_values from BinaryConversation Where WorkingNumber = 0
Order BY Number
;
Thanks to all those bloggers from whom I learn.
Here's a good resource I found on Binary and Decimal.
Here's a good resource I found on Binary and Decimal.
Friday, February 28, 2014
SSIS: Script task to check for File Exsits or not and send email notification
Sometime within SSIS package, we have to check for a particular file. If the file exists, then we have to do whole
lot of Data Flow and transformations. So if this is the case, we should in first step check for file existence.
If file does not exists, we want to send a email notification to business user and let them know that the file is missing.
To do this, let's get started.
Step 1
======
First we need to define following variables.
varFileExists Boolean datatype default value False
varFullSourceFilePath string datatype value will be location of the file with fully qualified. So if your file
is some server (most cases, it should be something like this \\myserver.com\Sourcefolder\myfile.txt). In our sample
case we will point to C drive. C:\tmp\a.xlsx

Step 2
======
Let's drag and drop a script task to control flow and open it. Add varFullSourcePathFileName in ReadOnlyVariable and varFileExists in readwritevariables as shown in the picture below.

Now open script task in visual basic. You can also do this in C#. But for now let's do in Visual Basic 2008.
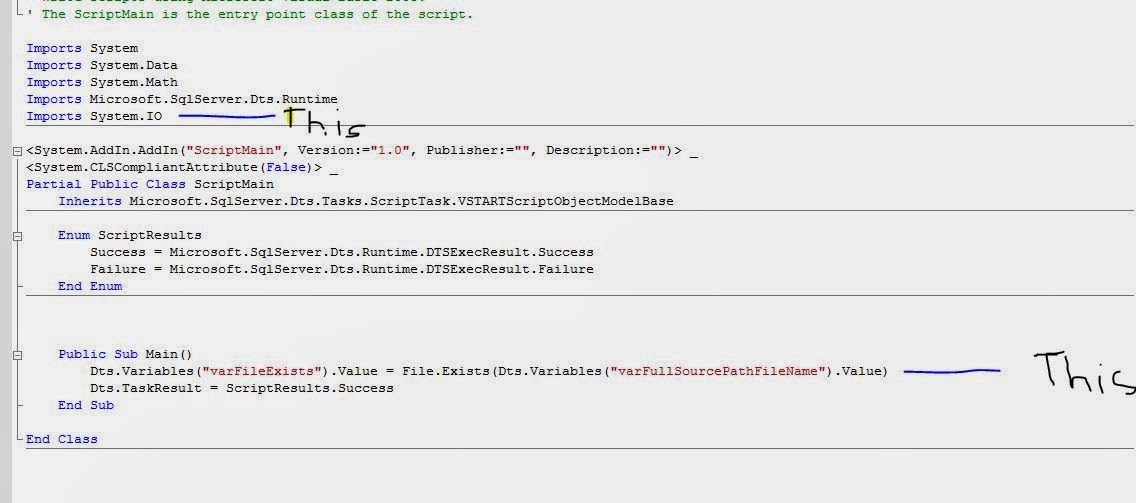
We need to add Imports System.IO and then write following code in Public Sub Main () routine.
Dts.Variables("varFileExists").Value = File.Exists(Dts.Variables("varFullSourcePathFileName").Value)
As shown in picture below.
Step 3
=====
Let's configure for send mail.
Add a data flow or sequence container to go to next step if File exists. If not send a mail. Here' we are interested in sending mail if file is missing.
So add a send mail task. connect script task to it. Change Evaluation Operation to Expression and Constraint. Value should be Success (be careful not to use Failure here) and in Expression write
@varFileExists==False.
This mean that file is missing and it will send mail notification.

And for your dataflow or sequence container, make @varFileExists==True and proceed.
lot of Data Flow and transformations. So if this is the case, we should in first step check for file existence.
If file does not exists, we want to send a email notification to business user and let them know that the file is missing.
To do this, let's get started.
Step 1
======
First we need to define following variables.
varFileExists Boolean datatype default value False
varFullSourceFilePath string datatype value will be location of the file with fully qualified. So if your file
is some server (most cases, it should be something like this \\myserver.com\Sourcefolder\myfile.txt). In our sample
case we will point to C drive. C:\tmp\a.xlsx
Step 2
======
Let's drag and drop a script task to control flow and open it. Add varFullSourcePathFileName in ReadOnlyVariable and varFileExists in readwritevariables as shown in the picture below.
Now open script task in visual basic. You can also do this in C#. But for now let's do in Visual Basic 2008.
We need to add Imports System.IO and then write following code in Public Sub Main () routine.
Dts.Variables("varFileExists").Value = File.Exists(Dts.Variables("varFullSourcePathFileName").Value)
As shown in picture below.
Step 3
=====
Let's configure for send mail.
Add a data flow or sequence container to go to next step if File exists. If not send a mail. Here' we are interested in sending mail if file is missing.
So add a send mail task. connect script task to it. Change Evaluation Operation to Expression and Constraint. Value should be Success (be careful not to use Failure here) and in Expression write
@varFileExists==False.
This mean that file is missing and it will send mail notification.
And for your dataflow or sequence container, make @varFileExists==True and proceed.
Wednesday, February 26, 2014
SQL: Get Current Financial Year dynamically in Select Statement.
Sometime, we are asked to write a query where we have to get a result set based on current financial year. Let's say my financial year begin 1st of November ever year and end 31st October.
And we have to do a select between these two date ranges.
Here's how we do it.
Select * from mytable
where myfinancialdate >= CASE WHEN month(getdate()) > 11
THEN convert(datetime, cast(year(getdate()) as varchar) + '-11-1')
ELSE convert(datetime, cast(year(getdate()) - 1 as varchar) + '-11-1') end
AND (myfinancialdate <= CASE WHEN month(getdate()) > 11
THEN convert(datetime, cast(year(getdate()) + 1 as varchar) + '-10-31')
ELSE convert(datetime, cast(year(getdate()) as varchar) + '-10-31') end);
This will result set only following between current financial year. For example in 2014 year, the result will bring value from 11-1-2013 to 10-31-2014.
Let say that we want to retrieve all the data from last fiscal year and current fiscal year. To do this, we can use this approach:
Let's declare some variable.
--Fiscal year variables
, @Now datetime = getdate()
, @CurrentFiscalYear_BeginDate date
, @PastFiscalYear_BeginDate date
, @CurrentFiscalYear_EndDate date
--Set Fiscal year values
select @CurrentFiscalYear_BeginDate = '11/1/' + cast(case when month(@Now) > 11 then year(@Now) else year(@Now)-1 end as varchar(4))
select
@PastFiscalYear_BeginDate = dateadd(year, -1, @CurrentFiscalYear_BeginDate) --decrement year of current FY begin date to get past FY begin date
, @CurrentFiscalYear_EndDate = dateadd(day, -1, dateadd(year, 1, @CurrentFiscalYear_BeginDate)) --increment year of current FY begin date to get next FY begin date and then subtract one day to get end date of current FY
Now we can use these variable to get data.
Select * from mytable
Where myfinancialdate
between @PastFiscalYear_BeginDate AND @CurrentFiscalYear_EndDate
This will retrieve all the row between last fiscal year and current fiscal year.
And we have to do a select between these two date ranges.
Here's how we do it.
Select * from mytable
where myfinancialdate >= CASE WHEN month(getdate()) > 11
THEN convert(datetime, cast(year(getdate()) as varchar) + '-11-1')
ELSE convert(datetime, cast(year(getdate()) - 1 as varchar) + '-11-1') end
AND (myfinancialdate <= CASE WHEN month(getdate()) > 11
THEN convert(datetime, cast(year(getdate()) + 1 as varchar) + '-10-31')
ELSE convert(datetime, cast(year(getdate()) as varchar) + '-10-31') end);
This will result set only following between current financial year. For example in 2014 year, the result will bring value from 11-1-2013 to 10-31-2014.
Let say that we want to retrieve all the data from last fiscal year and current fiscal year. To do this, we can use this approach:
Let's declare some variable.
--Fiscal year variables
, @Now datetime = getdate()
, @CurrentFiscalYear_BeginDate date
, @PastFiscalYear_BeginDate date
, @CurrentFiscalYear_EndDate date
--Set Fiscal year values
select @CurrentFiscalYear_BeginDate = '11/1/' + cast(case when month(@Now) > 11 then year(@Now) else year(@Now)-1 end as varchar(4))
select
@PastFiscalYear_BeginDate = dateadd(year, -1, @CurrentFiscalYear_BeginDate) --decrement year of current FY begin date to get past FY begin date
, @CurrentFiscalYear_EndDate = dateadd(day, -1, dateadd(year, 1, @CurrentFiscalYear_BeginDate)) --increment year of current FY begin date to get next FY begin date and then subtract one day to get end date of current FY
Now we can use these variable to get data.
Select * from mytable
Where myfinancialdate
between @PastFiscalYear_BeginDate AND @CurrentFiscalYear_EndDate
This will retrieve all the row between last fiscal year and current fiscal year.
Thursday, February 20, 2014
How to find indexes and statics on a particular table in SQL Server
How to find indexes and statics on a particular table in SQL Server.
Generally we create indexes on any table in a database to increase data retrieval process. So when we create an index (Clustered Indexes or Non-Clustered indexes) we think that this is all we need to do.
However as data are inserted or deleted as time flies by, these indexes will be out of sync based on new set of data.
As a developer or dba, we should keep in mind that we should periodically check all the indexes on our database and see when was last time it was updated. This can help a lot in performance improvement in production environment.
So let's get into some technical aspect of indexes.
How we create indexes?-- You can find many resources online
Clustered vs. Non-Clustered indexes.-- You can find many resources online
So after creating al these indexes, how do we go and check that what all indexes exists on a particular table and when was it last updated?
To begin with, we will have to look at the table called sys.indexes which hold all indexes information. Table name in sys.indexes is hidden in Object_ID values which we will have to convert to read.
So begin with wild select on this table.
Select * From Sys.Indexes;
Some important columns are following:
object_id = your table ID
name = Name of the index
index_id = IndexID
is_unique
is_primary_key = does it have a primary key as part of index
is_unique_constraint
fill_factor = default value is 80 percent
has_filter = does your index have filter or not
Now we want to know what all indexes exist on my table. Let's say I have a table 'dbo.Mytable'
To find this out let's run this query.
SELECT name AS index_name
, STATS_DATE(OBJECT_ID, index_id) AS StatsUpdated
FROM sys.indexes
WHERE OBJECT_ID = OBJECT_ID('dbo.Mytable');
This query will return two columns Index_Name and statsUpdated (date when it was updated last time). Based on this, you can find out when was your indexes last built and if you need to rebuild them or not.
Update:
This sql will provide you the name of index on your table, type of index and percent of fragmentation.
SELECT a.index_id, name, a.index_type_desc, a.page_count, avg_fragmentation_in_percent
FROM sys.dm_db_index_physical_stats (DB_ID(), OBJECT_ID(N'Schema.TableName'),
NULL, NULL, NULL) AS a
JOIN sys.indexes AS b ON a.object_id = b.object_id AND a.index_id = b.index_id;
Generally we create indexes on any table in a database to increase data retrieval process. So when we create an index (Clustered Indexes or Non-Clustered indexes) we think that this is all we need to do.
However as data are inserted or deleted as time flies by, these indexes will be out of sync based on new set of data.
As a developer or dba, we should keep in mind that we should periodically check all the indexes on our database and see when was last time it was updated. This can help a lot in performance improvement in production environment.
So let's get into some technical aspect of indexes.
How we create indexes?-- You can find many resources online
Clustered vs. Non-Clustered indexes.-- You can find many resources online
So after creating al these indexes, how do we go and check that what all indexes exists on a particular table and when was it last updated?
To begin with, we will have to look at the table called sys.indexes which hold all indexes information. Table name in sys.indexes is hidden in Object_ID values which we will have to convert to read.
So begin with wild select on this table.
Select * From Sys.Indexes;
Some important columns are following:
object_id = your table ID
name = Name of the index
index_id = IndexID
is_unique
is_primary_key = does it have a primary key as part of index
is_unique_constraint
fill_factor = default value is 80 percent
has_filter = does your index have filter or not
Now we want to know what all indexes exist on my table. Let's say I have a table 'dbo.Mytable'
To find this out let's run this query.
SELECT name AS index_name
, STATS_DATE(OBJECT_ID, index_id) AS StatsUpdated
FROM sys.indexes
WHERE OBJECT_ID = OBJECT_ID('dbo.Mytable');
This query will return two columns Index_Name and statsUpdated (date when it was updated last time). Based on this, you can find out when was your indexes last built and if you need to rebuild them or not.
Update:
This sql will provide you the name of index on your table, type of index and percent of fragmentation.
SELECT a.index_id, name, a.index_type_desc, a.page_count, avg_fragmentation_in_percent
FROM sys.dm_db_index_physical_stats (DB_ID(), OBJECT_ID(N'Schema.TableName'),
NULL, NULL, NULL) AS a
JOIN sys.indexes AS b ON a.object_id = b.object_id AND a.index_id = b.index_id;
Tuesday, February 11, 2014
SSIS: Logging total number of rows inserted in multiple tables.
Suppose you are inserting multiple rows in different staging tables in a single package. And you have to log total number of rows inserted into a logging table for audit purpose. How do we do it.
Let's see how we can accomplish this inside a ssis package.
Say we are loading data in 3 tables.
Table A,
Table B,
and Table C.
Let's create a variable "varSrcRowCountAL" int data type.
Add a SQL Execute task and set Result Set to "Single Row". In SQL Statement Add following sql statement
Select ( (Select count(*) From TableA) + (Select count(*) From TableB) + (Select count(*) From [TableC));
In Result Set tab of SQL Execute task, Add variable like this
Result Name = 0
Variable Name = User::varSrcRowCountAL
This will save total row count in our variable.
Now add another SQL Execute Task to truncate TableA, TableB and TableC
Add a sequence container, add three data flow task to load your data to 3 three table.
Outside your sequence container, add another SQL Execute Task.
This time, define a variable called "varDestRowCountAL" int datatype. In SQL Statement Add following sql statement.
Select ( (Select count(*) From TableA) + (Select count(*) From TableB) + (Select count(*) From [TableC));
This value we will save in our destination variable varDestRowCountAL. Do the same as you did to count to your source count.
Now we can use this variable to update our logging table.
Let's see how we can accomplish this inside a ssis package.
Say we are loading data in 3 tables.
Table A,
Table B,
and Table C.
Let's create a variable "varSrcRowCountAL" int data type.
Add a SQL Execute task and set Result Set to "Single Row". In SQL Statement Add following sql statement
Select ( (Select count(*) From TableA) + (Select count(*) From TableB) + (Select count(*) From [TableC));
In Result Set tab of SQL Execute task, Add variable like this
Result Name = 0
Variable Name = User::varSrcRowCountAL
This will save total row count in our variable.
Now add another SQL Execute Task to truncate TableA, TableB and TableC
Add a sequence container, add three data flow task to load your data to 3 three table.
Outside your sequence container, add another SQL Execute Task.
This time, define a variable called "varDestRowCountAL" int datatype. In SQL Statement Add following sql statement.
Select ( (Select count(*) From TableA) + (Select count(*) From TableB) + (Select count(*) From [TableC));
This value we will save in our destination variable varDestRowCountAL. Do the same as you did to count to your source count.
Now we can use this variable to update our logging table.
Monday, February 10, 2014
Derived Columns with CTEs
Derived Columns with CTEs.
Let's say we have a simple query selecting few columns from some table. Now we are asked do some derived columns from this queries. However, some of these derived columns
are based another derived columns.
One way to do this is to create a view and get a first set of derived columns and than create another view on the first view to derive another sets of columns.
However there is another approach to do this. Take the initial query results and put into a common table expression, use another common table expression to get a first derived columns and
use it derive next set of columns. Theoretically this can be done n-times but to illustrate this, let's try to limit this to 3 CTEs.
This is simple table I have created to demonstrate derived columns from CTEs. Not a perfect but just to illustrate the concept.
Create table Student_Grade
(ID int IDENTITY,
FirstName varchar(50),
MiddleName varchar(10),
LastName varchar(50),
Maths float,
Biology float,
Chemistry float,
Physics float,
English float,
ForeignLanguage float,
Physical_Education float
)
--Let's enter some data in our sample tables.
Insert into Student_Grade
VALUES
('Abby', 'M', 'Smith',40,67,38,25,67,71,34),
('Bbby', 'M', 'Smith',50,77,48,35,57,72,44),
('Cbby', 'M', 'Smith',68,87,58,45,67,73,54),
('Dbby', 'M', 'Smith',78,97,68,55,27,74,64),
('Ebby', 'M', 'Smith',88,57,78,65,17,75,74)
--Let's see if we have our data in the table or not.
Select * from Student_Grade;
-- Let's say we are asked to find what student made in total_science_score, combined average in Science subjects (Biology, physics, and Chemistry) and English and ForeignLanguage.
With FirstSelect AS
(
SELECT [ID]
,[FirstName]
,[MiddleName]
,[LastName]
,[Maths]
,[Biology]
,[Chemistry]
,[Physics]
,[English]
,[ForeignLanguage]
,[Physical_Education]
FROM [dbo].[Student_Grade]
),
--Here for simple purpose I am deriving two columns -Total_Science_Score and Total_language_Score
SecondSelect AS
( Select [ID]
,[FirstName]
,[MiddleName]
,[LastName]
,[Maths]
,[Biology]
,[Chemistry]
,[Physics]
,[English]
,[ForeignLanguage]
,[Physical_Education]
,[Biology]+[Chemistry]+ [Physics] As Total_Science_Score
,[English]+[ForeignLanguage] As Total_language_Score
From FirstSelect
),
--Here I am deriving another columns which was derived in previous statement
ThirdSelect AS
(
Select
[ID]
,[FirstName]
,[MiddleName]
,[LastName]
,[Maths]
,[Biology]
,[Chemistry]
,[Physics]
,[English]
,[ForeignLanguage]
,[Physical_Education]
,Total_Science_Score
,Total_language_Score
, Total_Science_Score + Total_language_Score AS Total_Science_Language_Score
from SecondSelect
)
Select * from ThirdSelect
Let's say we have a simple query selecting few columns from some table. Now we are asked do some derived columns from this queries. However, some of these derived columns
are based another derived columns.
One way to do this is to create a view and get a first set of derived columns and than create another view on the first view to derive another sets of columns.
However there is another approach to do this. Take the initial query results and put into a common table expression, use another common table expression to get a first derived columns and
use it derive next set of columns. Theoretically this can be done n-times but to illustrate this, let's try to limit this to 3 CTEs.
This is simple table I have created to demonstrate derived columns from CTEs. Not a perfect but just to illustrate the concept.
Create table Student_Grade
(ID int IDENTITY,
FirstName varchar(50),
MiddleName varchar(10),
LastName varchar(50),
Maths float,
Biology float,
Chemistry float,
Physics float,
English float,
ForeignLanguage float,
Physical_Education float
)
--Let's enter some data in our sample tables.
Insert into Student_Grade
VALUES
('Abby', 'M', 'Smith',40,67,38,25,67,71,34),
('Bbby', 'M', 'Smith',50,77,48,35,57,72,44),
('Cbby', 'M', 'Smith',68,87,58,45,67,73,54),
('Dbby', 'M', 'Smith',78,97,68,55,27,74,64),
('Ebby', 'M', 'Smith',88,57,78,65,17,75,74)
--Let's see if we have our data in the table or not.
Select * from Student_Grade;
-- Let's say we are asked to find what student made in total_science_score, combined average in Science subjects (Biology, physics, and Chemistry) and English and ForeignLanguage.
With FirstSelect AS
(
SELECT [ID]
,[FirstName]
,[MiddleName]
,[LastName]
,[Maths]
,[Biology]
,[Chemistry]
,[Physics]
,[English]
,[ForeignLanguage]
,[Physical_Education]
FROM [dbo].[Student_Grade]
),
--Here for simple purpose I am deriving two columns -Total_Science_Score and Total_language_Score
SecondSelect AS
( Select [ID]
,[FirstName]
,[MiddleName]
,[LastName]
,[Maths]
,[Biology]
,[Chemistry]
,[Physics]
,[English]
,[ForeignLanguage]
,[Physical_Education]
,[Biology]+[Chemistry]+ [Physics] As Total_Science_Score
,[English]+[ForeignLanguage] As Total_language_Score
From FirstSelect
),
--Here I am deriving another columns which was derived in previous statement
ThirdSelect AS
(
Select
[ID]
,[FirstName]
,[MiddleName]
,[LastName]
,[Maths]
,[Biology]
,[Chemistry]
,[Physics]
,[English]
,[ForeignLanguage]
,[Physical_Education]
,Total_Science_Score
,Total_language_Score
, Total_Science_Score + Total_language_Score AS Total_Science_Language_Score
from SecondSelect
)
Select * from ThirdSelect
Subscribe to:
Posts (Atom)